
NAND no va a desaparecer, pero los servidores de IA ahora dependen de algo más que solo flash
Durante más de dos décadas, GetUSB ha estado analizando cómo se mueve realmente la información, no solo cómo se presenta en marketing. En ese tiempo, hemos visto cómo el almacenamiento ha evolucionado a través de varios ciclos, desde la caída de los discos mecánicos hasta el auge del flash, y más recientemente hacia sistemas donde el almacenamiento ya no es solo un componente pasivo, sino parte activa de la infraestructura.
Lo que está ocurriendo ahora con la infraestructura de IA se siente como otro de esos puntos de transición, pero impulsado por un tipo de presión diferente.
La memoria NAND no va a desaparecer, y realmente no hay discusión sobre eso. Sigue siendo la base del almacenamiento moderno, y hace ese trabajo extremadamente bien. Al mismo tiempo, la demanda de NAND ha ido aumentando rápidamente, en gran parte debido a las cargas de trabajo de IA que requieren conjuntos de datos enormes y acceso constante a ellos. Esa demanda está empezando a chocar con la oferta de formas que cada vez son más difíciles de ignorar, ya sea en forma de presión en precios, asignaciones más ajustadas o simplemente tiempos de entrega más largos para grandes implementaciones.
Cuando este tipo de desequilibrio empieza a aparecer, la industria no se queda quieta esperando a que todo se normalice. Empieza a buscar otras formas de resolver el problema, y ahí es donde las cosas comienzan a cambiar.
La suposición que todos hacen
Si lo miras desde fuera, la lógica sigue pareciendo bastante razonable. Los modelos de IA son cada vez más grandes, los datasets continúan creciendo y se está construyendo más infraestructura para soportarlo todo, así que la respuesta natural es añadir más almacenamiento. Más SSD, más capacidad, más flash en el rack, y el sistema debería poder mantenerse al ritmo.
Ese enfoque ha funcionado durante mucho tiempo, y en muchos entornos todavía funciona. Sin embargo, la suposición detrás de esto es que el almacenamiento se comporta de la misma manera bajo cargas de trabajo de IA que bajo cargas más tradicionales, y ahí es donde las cosas empiezan a desviarse.
También se asume que la NAND seguirá estando disponible en las cantidades necesarias y a precios predecibles, algo que cada vez es menos seguro a medida que la demanda se acelera.
Donde NAND empieza a mostrar sus límites
La memoria NAND es excepcionalmente buena en aquello para lo que fue diseñada. Proporciona almacenamiento denso, fiable y relativamente rápido, y para la computación de propósito general resolvió una larga lista de problemas que existían con tecnologías anteriores. Incluso hoy, para la mayoría de las cargas de trabajo, funciona exactamente como se espera.
Sin embargo, las cargas de trabajo de IA están pidiendo algo ligeramente diferente, y esa diferencia es más importante de lo que puede parecer a primera vista.
En lugar de simplemente almacenar datos y recuperarlos cuando se necesitan, estos sistemas requieren un flujo constante y continuo de datos hacia recursos de cómputo altamente paralelos, muchas veces a velocidades que son difíciles de mantener de forma consistente con arquitecturas de almacenamiento tradicionales. Los SSD de alto rendimiento pueden manejar picos de actividad y grandes colas de transacciones, pero alimentar miles de núcleos de GPU en tiempo real es un tipo de demanda completamente distinto.
Al mismo tiempo, el medio subyacente – la NAND en sí – se está volviendo más caro y, en algunos casos, más difícil de asegurar en grandes volúmenes. Así que ahora la industria está lidiando con dos presiones al mismo tiempo: la necesidad de un mayor y más consistente throughput de datos, y la realidad de que el medio principal utilizado para entregar esos datos está bajo presión tanto de suministro como de costo.
Esa combinación es la que está impulsando el cambio actual. No porque la NAND haya dejado de funcionar, sino porque depender únicamente de ella ya no es suficiente para seguir el ritmo de lo que los sistemas de IA están intentando hacer.
La industria no reemplazó NAND – construyó alrededor de ella
Lo que está empezando a ocurrir en la infraestructura de IA no es un reemplazo limpio de la NAND, ni un cambio repentino donde el flash desaparece de la ecuación. De hecho, la NAND sigue estando muy presente en el centro de estos sistemas. La diferencia es que ya no se espera que soporte toda la carga por sí sola.
En su lugar, la industria está construyendo capas adicionales a su alrededor, cada una diseñada para manejar una parte específica de la carga de trabajo que la NAND nunca estuvo realmente pensada para abordar por sí sola. En la práctica, esto significa replantear cómo se mueve la información dentro de un sistema, dónde se ubica en distintas etapas y con qué rapidez debe ser accesible dependiendo de lo que esté haciendo la parte de cómputo.
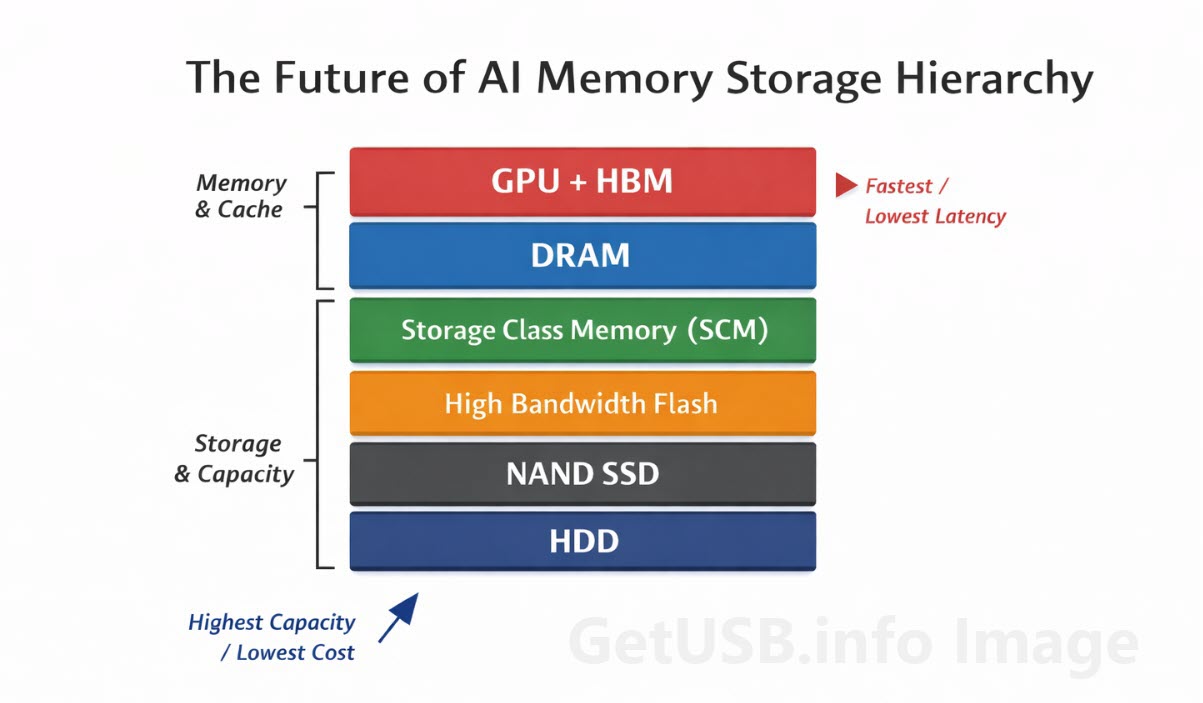
Aquí es donde empieza a aparecer con más frecuencia el concepto de una pila de memoria. No como un término de marketing, sino como una forma práctica de describir lo que realmente se está implementando. En lugar de tratar almacenamiento y memoria como dos categorías separadas, los sistemas de IA están empezando a difuminar esa línea, creando múltiples niveles que se comportan de forma diferente dependiendo de la velocidad, el costo y la proximidad al procesador.
La NAND sigue desempeñando un papel crítico en esa pila, especialmente en lo que respecta a la capacidad, pero ahora se sitúa junto a otras tecnologías diseñadas para manejar las partes de la carga de trabajo donde la latencia y el ancho de banda importan más que el volumen bruto de almacenamiento.
Qué se está construyendo alrededor de NAND
Una vez que miras el sistema de esta manera, los cambios empiezan a tener más sentido. En lugar de intentar forzar a la NAND a hacerlo todo, la industria está introduciendo otras capas que resuelven problemas específicos. Algunas de estas ya están en producción, otras todavía están evolucionando, pero juntas forman la estructura en la que los servidores modernos de IA están empezando a apoyarse.
En la siguiente serie de artículos, vamos a profundizar en cada una de estas capas por separado, porque cada una merece más espacio del que un artículo pilar puede ofrecer razonablemente. Por ahora, el objetivo es mostrar cómo encajan todas las piezas para que este artículo se sostenga por sí mismo mientras también prepara el terreno para los análisis más detallados que vendrán.
High Bandwidth Memory (HBM)
En la parte más alta de la pila, lo más cerca posible de la GPU, se encuentra la High Bandwidth Memory, o HBM. Se trata de un tipo de DRAM apilada que se sitúa físicamente cerca del procesador y está diseñada para ofrecer un throughput de datos extremadamente alto con una latencia muy baja. No es un dispositivo de almacenamiento en el sentido tradicional, sino una forma especializada de memoria creada específicamente para mantener a las GPUs modernas alimentadas con datos al ritmo que necesitan.
HBM no trata sobre capacidad. Trata sobre mantener ocupada la GPU, que en los sistemas de IA suele ser el componente más caro del rack. Si ese procesador está esperando datos, todo lo que está detrás pierde eficiencia. HBM aborda este problema priorizando el ancho de banda y la proximidad por encima del tamaño.
Si lo piensas en términos de almacén, HBM es como tener el siguiente pallet de producto ya colocado justo en el muelle de carga, sin envolver y listo para moverse. No estás aumentando la cantidad total de inventario del almacén, pero sí estás asegurando que la carretilla elevadora nunca tenga que detenerse esperando el siguiente lote.
Para una mirada más profunda sobre cómo HBM se compara con alternativas emergentes, lo hemos cubierto aquí: HBM vs HBF: Why the Memory Hierarchy is Being Stretched
Storage Class Memory (SCM)
Justo por debajo de eso se encuentra una categoría que, en la práctica, no existía realmente hace unos años: almacenamiento que se comporta más como memoria.
Storage Class Memory, o SCM, llena el espacio entre la DRAM y la NAND. No tiene la velocidad de la memoria pura, ni la densidad del flash, pero ofrece un equilibrio que la hace útil para cargas de trabajo que necesitan un acceso más rápido que el que puede proporcionar la NAND sin asumir el costo completo de escalar DRAM.
En entornos de IA, este tipo de capa intermedia ayuda a absorber parte de la presión que de otro modo recaería directamente sobre la NAND, especialmente cuando se trata de conjuntos de datos de trabajo grandes que no encajan de forma limpia dentro de la memoria tradicional.
La analogía más sencilla es pensar en SCM como el área de preparación entre las estanterías principales del almacén y el muelle de carga. El almacén puede contener todo, pero es demasiado lento ir constantemente a buscar cajas a los pasillos cada vez que un camión necesita más producto. El muelle es rápido, pero el espacio es limitado. SCM es ese espacio intermedio donde se colocan los envíos más probables, listos para moverse, de manera que la operación continúe sin intentar convertir el muelle en todo el almacén.
High Bandwidth Flash
Aquí es donde las cosas empiezan a ponerse especialmente interesantes, porque en lugar de introducir un tipo completamente diferente de memoria, la industria también está buscando formas de llevar la NAND a un nuevo terreno.
High Bandwidth Flash es un intento de hacer que el flash se comporte menos como un dispositivo de almacenamiento tradicional y más como una extensión de la memoria. El objetivo no es reemplazar la NAND, sino cambiar la forma en que se accede a ella y se integra para que pueda entregar datos de forma más eficiente a las capas superiores.
En cierto modo, esto es la NAND adaptándose al nuevo entorno en lugar de ser reemplazada por él, lo cual encaja con lo que hemos visto en transiciones anteriores. Las tecnologías rara vez desaparecen de un día para otro; evolucionan para seguir siendo relevantes.
DRAM y sus límites
La DRAM sigue desempeñando un papel central en todo esto, y tampoco va a desaparecer. Sigue siendo la memoria de trabajo principal para la mayoría de los sistemas, incluidos los servidores de IA, y gestiona una gran parte de los datos activos que necesitan ser accedidos rápidamente.
Al mismo tiempo, escalar la DRAM de forma indefinida no es práctico. El costo, el consumo de energía y las limitaciones físicas entran en juego, especialmente a medida que los sistemas crecen. Como resultado, la DRAM por sí sola no puede absorber toda la demanda adicional creada por las cargas de trabajo de IA, lo que explica en parte por qué se están introduciendo estas otras capas.
En términos de almacén, la DRAM es como el suelo del muelle de carga. Es donde ocurre el trabajo activo, donde las cajas se abren, se clasifican y se mueven al siguiente paso lo más rápido posible. El problema es que solo puedes construir una cierta cantidad de espacio en el muelle antes de que el costo, la energía y el diseño dejen de tener sentido. En algún punto, necesitas zonas de preparación cercanas y almacenamiento más profundo detrás, porque intentar hacer toda la operación únicamente en el muelle se vuelve caro e ineficiente.
El regreso silencioso de los discos duros
Incluso con todo el enfoque en memoria de alta velocidad y flash, los discos duros tradicionales siguen formando parte del panorama, especialmente en la parte más baja de la pila donde el costo por terabyte importa más que la velocidad.
Los sistemas de IA generan y consumen enormes cantidades de datos, y no todos necesitan residir en almacenamiento de alto rendimiento. Los conjuntos de entrenamiento, los archivos históricos y la información a la que se accede con menor frecuencia siguen necesitando un lugar donde vivir, y para eso, los discos duros siguen siendo una de las opciones más económicas disponibles.
No compiten con la NAND ni con la memoria en rendimiento, pero reducen la presión global sobre esas capas al encargarse de los requisitos de almacenamiento masivo.
Acercar el cómputo al almacenamiento
Otro cambio que está ganando atención es la idea de reducir la distancia que los datos necesitan recorrer en primer lugar. En lugar de mover constantemente grandes volúmenes de datos entre almacenamiento y cómputo, algunas arquitecturas están empezando a acercar el procesamiento a donde reside la información.
Este enfoque no elimina la necesidad de memoria o almacenamiento rápidos, pero sí cambia el equilibrio. Al manejar ciertas operaciones más cerca de los datos, los sistemas pueden reducir cuellos de botella y mejorar la eficiencia general sin depender únicamente de medios más rápidos.
El papel del contexto en IA (KV cache)
Uno de los factores menos evidentes que impulsa todo esto es la cantidad de datos temporales que generan los modelos de IA mientras están en ejecución. Esto se conoce comúnmente como contexto o KV cache, y representa el estado de trabajo del modelo a medida que procesa entradas y genera salidas.
Esos datos no siempre encajan perfectamente dentro de la memoria tradicional, especialmente a gran escala, lo que explica por qué los sistemas están empezando a tratar el almacenamiento como una extensión de la memoria en lugar de una capa completamente separada. Es otro ejemplo de cómo los límites entre estas categorías se están volviendo cada vez más difusos.
Aquí también funciona la analogía del almacén. El KV cache es como la lista activa de pedidos y el portapapeles en uso para todo lo que se está empaquetando, clasificando y enviando en ese momento. No es el inventario completo ni el almacenamiento a largo plazo, pero si ese registro activo se vuelve demasiado grande o difícil de acceder, toda la operación se ralentiza porque nadie tiene claro qué se acaba de recoger, qué sigue y en qué punto está el pedido actual.
La nueva pila de memoria de IA
Cuando te alejas y observas el sistema en su conjunto, empieza a parecerse más a una estructura por capas que a una jerarquía simple.
En la parte superior, tienes la GPU junto con HBM, gestionando operaciones inmediatas de alta velocidad. Justo detrás está la DRAM, manejando cargas activas que requieren acceso rápido pero que no necesitan estar directamente en el procesador. Más abajo, capas emergentes como SCM y el flash de alto ancho de banda ayudan a cerrar la brecha entre memoria y almacenamiento, proporcionando capacidad adicional sin sacrificar demasiado rendimiento.
Más abajo, la NAND tradicional sigue encargándose del almacenamiento a gran escala, mientras que los discos duros asumen el papel de retención de datos a largo plazo de forma rentable.
Si imaginas todo esto como un almacén, la estructura se vuelve más fácil de entender. HBM es el pallet esperando en el muelle, DRAM es el suelo del muelle donde ocurre el trabajo activo, SCM es el área de preparación justo detrás, NAND son las estanterías principales del almacén y los discos duros son el almacenamiento profundo en la parte trasera donde el costo y la capacidad importan más que la velocidad. El sistema funciona porque cada capa tiene un rol, y porque nadie espera que la parte trasera del almacén haga el trabajo del muelle de carga.
Cada capa cumple una función, y juntas forman un sistema que se adapta mucho mejor a las demandas de la IA que cualquier tecnología individual por sí sola.
Qué significa esto hacia adelante
La conclusión aquí no es que la NAND esté siendo reemplazada, ni que una sola tecnología nueva esté ocupando su lugar. Lo que está ocurriendo es más gradual y, en muchos sentidos, más interesante.
La industria está reconociendo que ninguna capa por sí sola puede manejarlo todo, especialmente bajo las exigencias de la IA. En lugar de forzar a una tecnología a estirarse más allá de sus límites, se está construyendo un sistema donde múltiples capas trabajan juntas, cada una optimizada para un rol específico.
Ese cambio modifica la forma en que pensamos sobre el almacenamiento. Ya no se trata solo de capacidad o incluso de velocidad bruta, sino de cómo se mueve la información a través del sistema y de qué tan eficientemente cada capa soporta a la que está por encima.
Y a medida que estas arquitecturas continúan evolucionando, la NAND sigue siendo una parte crítica del panorama – simplemente ya no es la única.
Tags: HBM, infraestructura AI, NAND flash, pila de memoria AI, storage class memory