La infraestructura de IA tiene una forma muy particular de dejar al descubierto límites que la mayoría de los sistemas nunca llegan a encontrar.
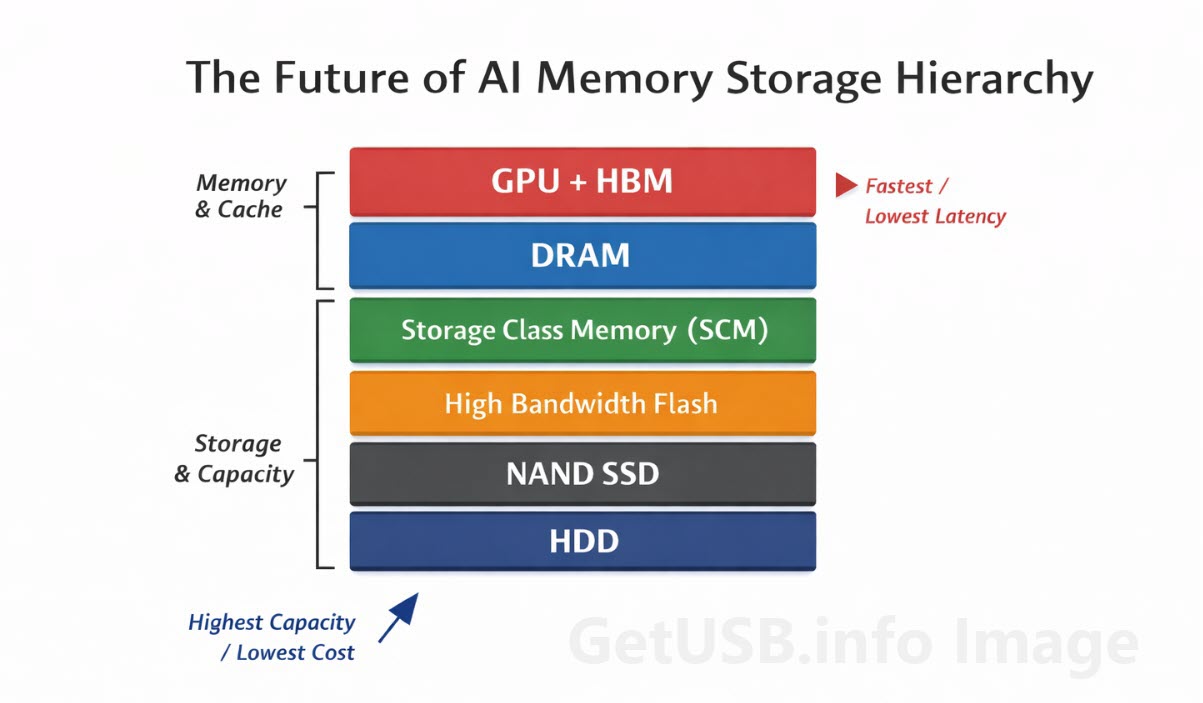
En los artículos anteriores vimos cómo la high bandwidth memory para cargas de trabajo de IA mantiene los datos lo más cerca posible de la GPU, y cómo la storage class memory entre DRAM y NAND ayuda a suavizar la brecha entre la memoria activa y el almacenamiento flash tradicional. Ambas capas existen porque el sistema no puede darse el lujo de esperar, ni siquiera por períodos cortos de tiempo, sin perder eficiencia.
Pero hay otra dirección hacia la que se está moviendo la industria, y no implica introducir un tipo de memoria completamente nuevo.
Más bien, se trata de tomar algo que ya existe, la memoria flash NAND, y empujarla hacia un papel para el que originalmente no fue diseñada.
Ahí es donde la idea de High Bandwidth Flash empieza a entrar en la conversación.
El problema que la NAND nunca estuvo pensada para resolver
La memoria flash NAND siempre se ha construido alrededor de una idea sencilla: almacenar una gran cantidad de datos de forma eficiente y recuperarlos cuando sea necesario.
Para la mayoría de las cargas de trabajo, ese modelo funciona perfectamente bien. Los datos permanecen en el almacenamiento, el sistema los solicita y el SSD los entrega con suficiente rapidez como para que casi nadie note realmente la demora.
Las cargas de trabajo de IA cambian esa dinámica.
En lugar de lecturas y escrituras ocasionales, estos sistemas están extrayendo datos en paralelo de forma constante, a menudo a través de miles de hilos, con muy poca tolerancia a cualquier inconsistencia en la entrega. No se trata solo de velocidad de manera aislada, sino de mantener un flujo constante de datos que mantenga el lado de cómputo totalmente aprovechado.
Ahí es donde el comportamiento tradicional de la NAND empieza a mostrar sus límites.
Incluso las unidades NVMe de alto rendimiento, con colas profundas y cifras sólidas de rendimiento, siguen operando dentro de un modelo de almacenamiento que asume ráfagas de actividad, no un flujo continuo de acceso parecido a la memoria.
Así que la pregunta pasa a ser esta: ¿qué sucede si dejas de tratar la NAND como almacenamiento y empiezas a tratarla más como parte del sistema de memoria?
Qué significa realmente “High Bandwidth Flash”
High Bandwidth Flash no es un estándar formal ni una sola categoría de producto.
Se entiende mejor como una dirección arquitectónica, y ahí es donde empieza a separarse de lo que cubrimos en High Bandwidth Memory.
La High Bandwidth Memory sigue siendo memoria. Es DRAM, construida y ubicada para ofrecer un acceso extremadamente rápido al estar físicamente cerca del procesador. Todo el sentido de HBM es la proximidad y la reducción de la latencia, llevar los datos lo más cerca posible del cómputo para que puedan ser accedidos casi al instante.
High Bandwidth Flash está resolviendo un problema diferente. Acepta que la NAND está más lejos dentro del sistema y que arrastra una latencia más alta, y en cambio se enfoca en cómo mover cantidades mucho mayores de datos en paralelo para que esa distancia importe menos.
En términos simples, HBM consiste en hacer que la memoria sea más rápida acercándola. High Bandwidth Flash consiste en hacer que el almacenamiento se comporte más rápido cambiando la manera en que se accede a él.
Esa distinción importa, porque el objetivo aquí no es convertir la NAND en DRAM. Es hacer que la NAND sea útil en situaciones donde el almacenamiento tradicional, de otro modo, ralentizaría el sistema.
El cambio ocurre a nivel de sistema, no solo a nivel del medio.
En lugar de un solo SSD atendiendo solicitudes de la forma tradicional, empiezas a ver muchos canales NAND operando en paralelo, controladores diseñados para concurrencia más que solo para capacidad, rutas de datos más amplias a través de interfaces PCIe Gen5 y Gen6, y capas de software que anticipan y preparan los datos antes de que se soliciten.
Tomados en conjunto, estos cambios no eliminan la latencia inherente de la NAND, pero sí reducen la frecuencia con la que esa latencia se convierte en el factor limitante dentro del sistema.
Una forma distinta de pensar en el ancho de banda
Cuando la gente escucha “alto ancho de banda”, normalmente asume que se trata de velocidad bruta.
Pero en este contexto, el ancho de banda en realidad tiene más que ver con cuántos datos se pueden mover al mismo tiempo y con qué consistencia puede mantenerse ese movimiento.
Las cargas de trabajo de IA no solo necesitan acceso rápido, necesitan acceso predecible a escala.
Si un clúster de GPU está extrayendo datos de forma desigual, incluso pequeñas variaciones pueden hacer que partes del sistema se detengan. Multiplica eso por cientos o miles de nodos, y esas ineficiencias empiezan a aparecer de maneras que se vuelven difíciles de ignorar.
High Bandwidth Flash es un intento de suavizar todo eso, no eliminando las características de la NAND, sino rodeándola con suficiente paralelismo e inteligencia para que esas características pesen menos en el sistema en su conjunto.
Extendiendo la analogía del almacén
Si seguimos usando el mismo modelo de almacén de los artículos anteriores, la NAND siempre ha sido el piso principal de almacenamiento.
Es donde vive todo, organizado en filas y estantes, optimizado para densidad y eficiencia más que para velocidad de acceso.
La DRAM es el muelle de carga, donde ocurre el trabajo activo. La SCM es el área de preparación justo detrás.
High Bandwidth Flash cambia la forma en que opera el almacén.
En lugar de un solo trabajador entrando en los pasillos para recoger artículos uno por uno, ahora tienes varios muelles de carga abiertos al mismo tiempo, varios montacargas moviéndose en paralelo, y artículos preposicionados según lo que el sistema espera necesitar después.
El almacén no ha cambiado en lo fundamental, pero sí ha cambiado la manera en que se accede a él.
No estás convirtiendo el almacén en el muelle de carga, estás haciendo que el almacén se comporte como si estuviera mucho más cerca de él.
Cómo se está construyendo esto en la práctica
La mayor parte de lo que permite High Bandwidth Flash no proviene de la propia NAND, sino de las capas que la rodean.
Los controladores ahora desempeñan un papel más importante en la forma en que se distribuyen los datos, centrándose en operaciones paralelas a través de múltiples dies y canales NAND en lugar de simplemente gestionar capacidad y desgaste. Al mismo tiempo, el ancho de banda de las interfaces sigue expandiéndose, dando a estos sistemas más margen para mover datos sin quedar limitados por el bus.
Lo que marca la mayor diferencia, sin embargo, es cómo interactúa el software con el hardware.
Los datos ya no se recuperan solo cuando se solicitan. Se predicen, se preparan, se almacenan en caché y se organizan de maneras que encajan con la forma en que se comportan las cargas de trabajo de IA. Eso significa anticipar patrones de acceso, mantener los datos usados con más frecuencia más cerca de la parte superior del stack y minimizar cuántas veces el sistema tiene que volver a rutas más lentas.
Nada de esto convierte a la NAND en memoria verdadera, pero sí le permite participar en el sistema de memoria de una forma más activa que antes.
Lo que todavía no es
Con todo este avance, es importante mantener las expectativas bien aterrizadas.
High Bandwidth Flash no hace que la NAND sea equivalente a la DRAM. Sigue estando basada en bloques, sigue teniendo una latencia mayor que cualquier forma de memoria real y sigue dependiendo en gran medida de controladores y software para rendir bien en entornos exigentes.
Esas limitaciones no desaparecen, simplemente se gestionan de forma más eficaz mediante el diseño del sistema.
Dónde encaja esto en la infraestructura de IA
En despliegues del mundo real, High Bandwidth Flash está apareciendo en sistemas que necesitan manejar conjuntos de datos extremadamente grandes sin empujar todo hacia niveles de memoria costosos.
Lo que esto realmente se ve en la práctica es un sistema que se apoya en la NAND de forma más activa que antes, no solo como un lugar donde se almacenan los datos, sino como parte de la ruta de datos de trabajo que alimenta los recursos de cómputo de una manera más continua.
En entornos de inferencia a gran escala, por ejemplo, los modelos y los datos de contexto a menudo superan lo que de forma realista cabe dentro de la DRAM. En lugar de forzarlo todo a la memoria, el sistema depende del acceso de alto rendimiento a la NAND, permitiendo que los datos fluyan lo suficientemente rápido como para comportarse más como una extensión de la memoria que como almacenamiento tradicional.
En entornos de entrenamiento, donde los conjuntos de datos se revisitan y procesan constantemente en paralelo, el objetivo cambia hacia mantener un flujo estable en lugar de manejar ráfagas aisladas. High Bandwidth Flash respalda eso manteniendo múltiples rutas de datos activas al mismo tiempo, reduciendo la posibilidad de que una sola solicitud se convierta en un cuello de botella.
Incluso en sistemas distribuidos con NVMe fabric, la idea sigue siendo la misma. Los datos están repartidos entre muchos dispositivos y nodos, pero se accede a ellos de forma coordinada, enfatizando el rendimiento sostenido y la disponibilidad por encima de la simple capacidad de almacenamiento. La NAND sigue haciendo el mismo trabajo fundamental, pero la forma en que el sistema interactúa con ella es mucho más dinámica de lo que solía ser.
El resultado final es que la NAND deja de comportarse como una capa distante en la parte inferior del stack y empieza a sentirse como parte del sistema activo, aunque nunca llegue por completo a las características de rendimiento de la memoria.
Por qué importa esta dirección
Si das un paso atrás y observas lo que está ocurriendo a lo largo de estos tres artículos, empieza a aparecer un patrón.
HBM acerca la memoria al cómputo. SCM reduce la brecha entre memoria y almacenamiento. High Bandwidth Flash empuja el almacenamiento más cerca de la memoria.
Todo está convergiendo hacia el mismo objetivo: reducir qué tan lejos tienen que viajar los datos y cuánto tiempo tiene que esperar el sistema por ellos.
Volviendo al panorama general
La NAND no va a desaparecer.
Si acaso, se está volviendo más importante, porque la cantidad total de datos que estos sistemas necesitan sigue creciendo.
Lo que está cambiando es cómo se está usando la NAND.
Ya no es solo una capa pasiva en la parte inferior del stack. Está siendo arrastrada hacia arriba, integrada más estrechamente y obligada a comportarse de maneras que se parecen cada vez más a la memoria, aunque nunca llegue a convertirse completamente en ella.
Ese cambio es exactamente lo que señalamos en la pieza original: la industria no reemplazó la NAND, construyó a su alrededor.
Qué viene después
A partir de aquí, el stack sigue evolucionando en ambas direcciones.
Arriba, la memoria se vuelve más rápida y más especializada. Abajo, el almacenamiento se vuelve más inteligente y más integrado. Y en algún punto en medio, la línea entre ambos sigue haciéndose cada vez más difícil de definir.
En la próxima entrega veremos cómo los sistemas de IA manejan los datos de trabajo en tiempo real y por qué conceptos como contexto y KV cache están empezando a influir en la forma en que memoria y almacenamiento se diseñan juntos.
Nota editorial
La perspectiva, la dirección y el enfoque técnico de este artículo fueron guiados por el autor, a partir de los temas específicos explorados a lo largo de la pieza y de la conversación más amplia sobre cómo la NAND está siendo empujada más cerca de la capa de memoria en la infraestructura de IA.
La IA se utilizó como asistente de redacción para ayudar con el ritmo, el flujo de las oraciones y la organización estructural, pero la dirección del tema, las comparaciones y la intención editorial final fueron determinadas por el autor.
La imagen que acompaña el artículo también fue creada con IA, no como una imagen genérica de stock, sino como una ilustración diseñada específicamente para reflejar conceptos propios del artículo que son difíciles de comunicar con imágenes convencionales, en particular la idea de que la memoria flash NAND se comporta más como una capa activa y adyacente a la memoria dentro de una arquitectura moderna de datos.
Todo el contenido fue revisado, refinado y aprobado por el autor antes de su publicación.