Understanding USB Technology Beyond the Marketing
Ongoing analysis of flash memory, USB technology, and data security - explained clearly for those who want to understand what's actually happening.
Core Knowledge Areas
Flash Storage
How NAND works, endurance myths, performance behavior, and pricing trends.
USB Security
Copy protection, data leakage risks, write protection, and compliance realities.
Data Integrity
Testing tools, fake capacity drives, corruption issues, and verification methods.
USB Hardware
What's inside a flash drive, firmware behavior, and performance tradeoffs.
Duplication Systems
Mass production copying, verification methods, and workflow design.
Industry Analysis
Market shifts, supply constraints, AI demand, and flash pricing dynamics.
Featured Analysis
Deep dives into real-world USB behavior, flash memory economics, controller decisions, and security tradeoffs.
Latest Articles

¿Las computadoras cuánticas reemplazarán al USB? Por qué la computación clásica sigue siendo importante

¿M.2 y NVMe son lo mismo? (Pista: no lo son)
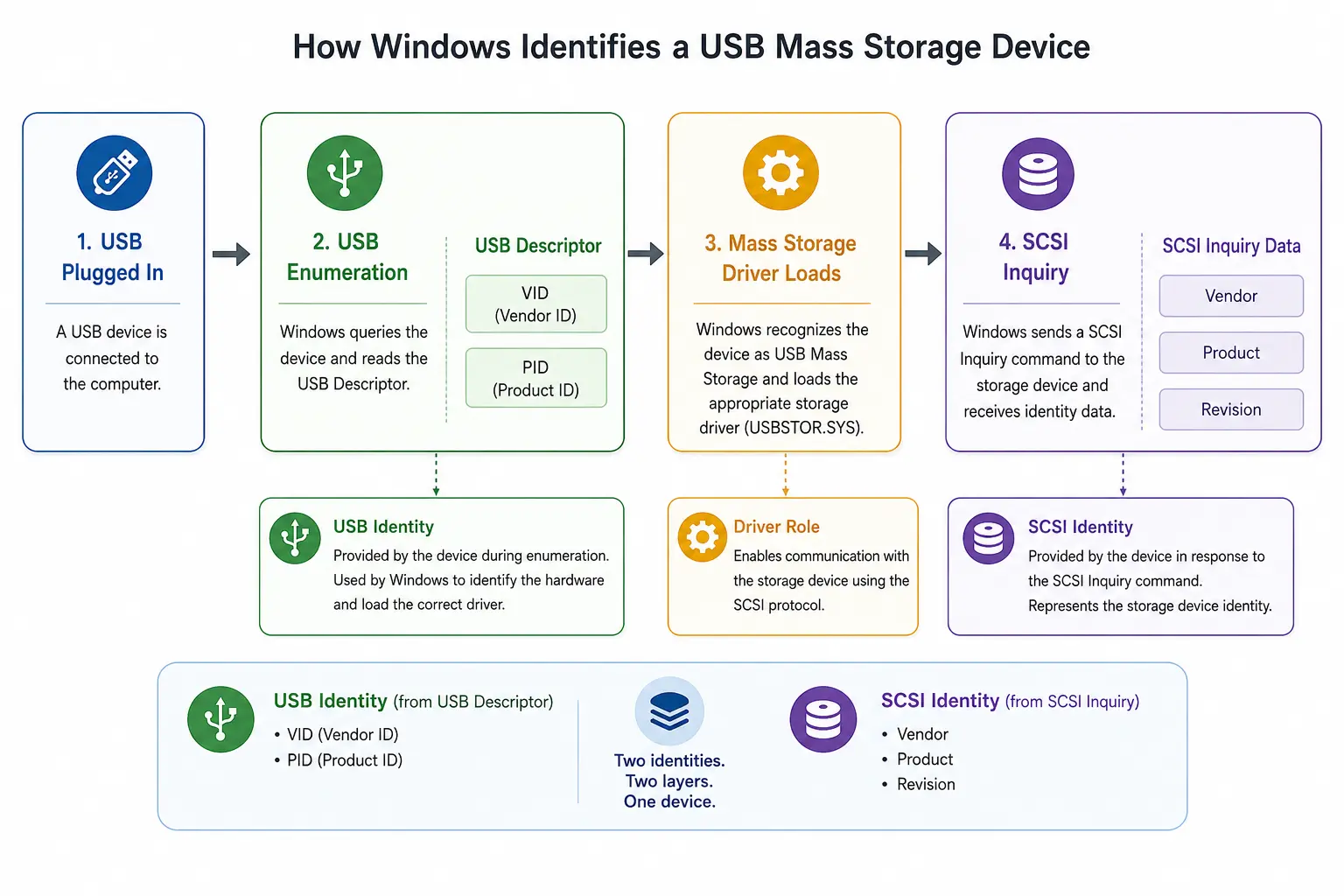
Cómo encontrar el VID, PID, proveedor SCSI y la información de producto de una memoria USB en Windows
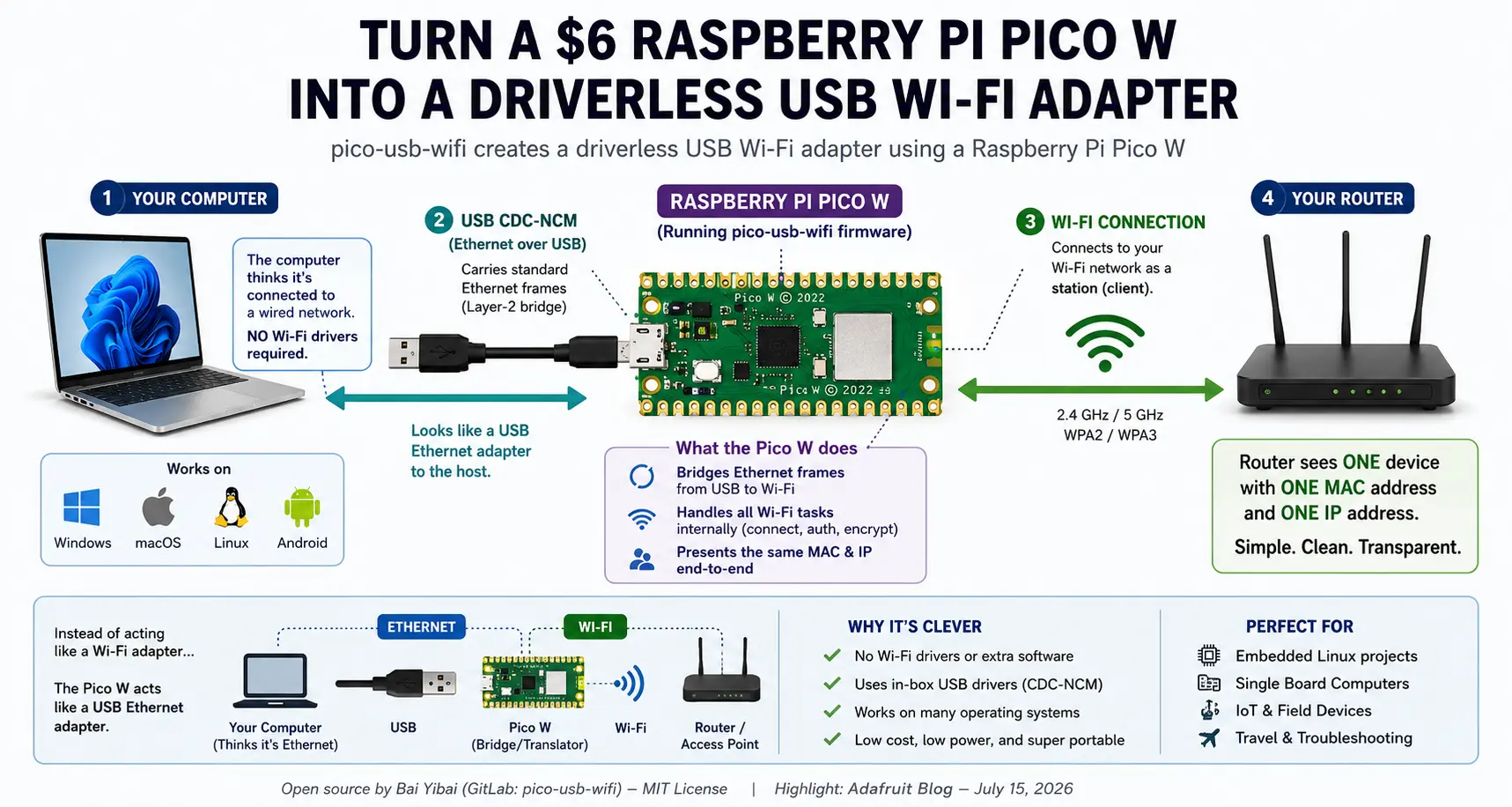
Alguien convirtió una Raspberry Pi Pico W de 6 dólares en un adaptador Wi-Fi USB sin controladores. Aquí está por qué es tan ingenioso
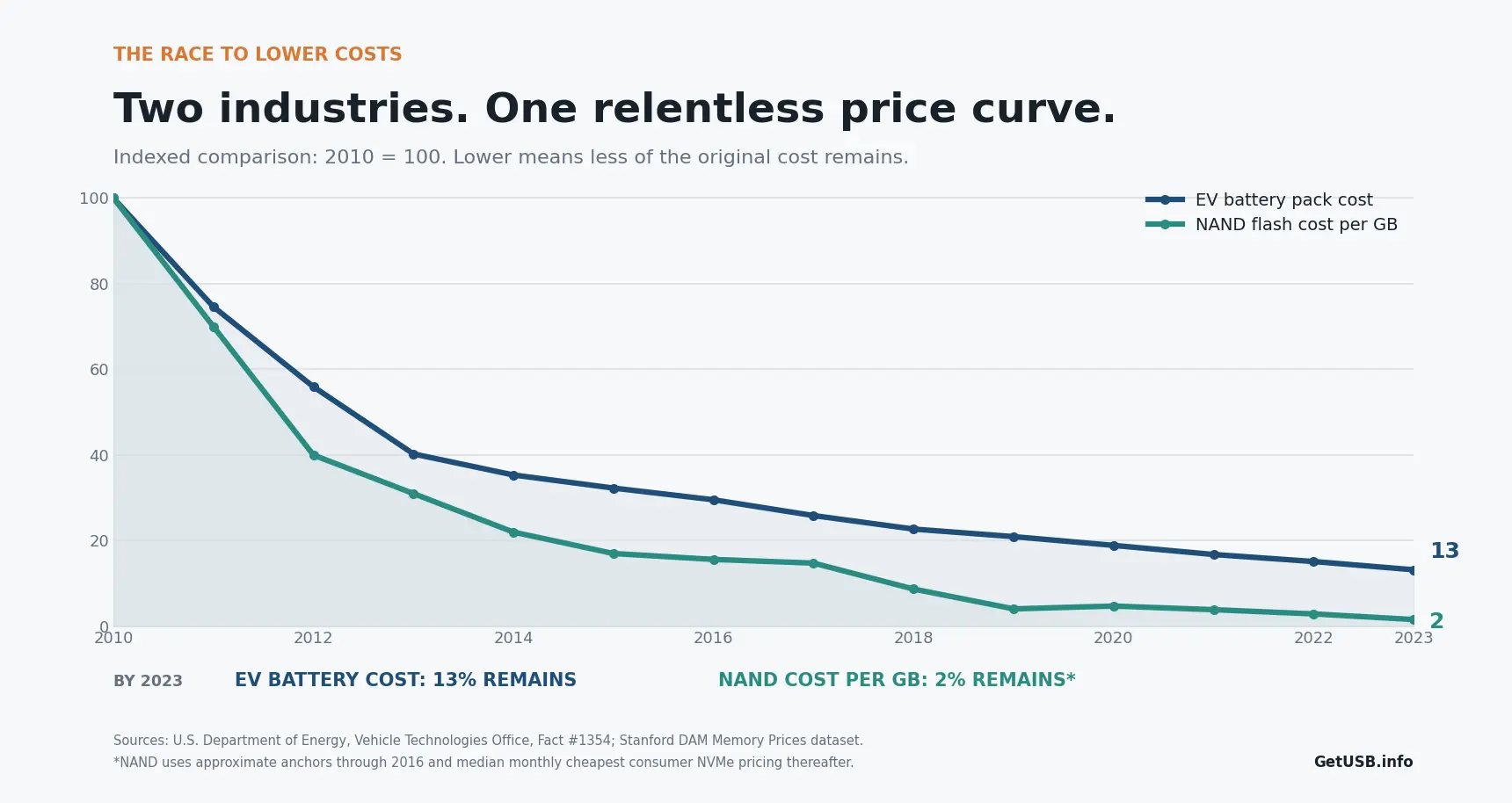
Miles de millones para construir. Centavos por unidad
