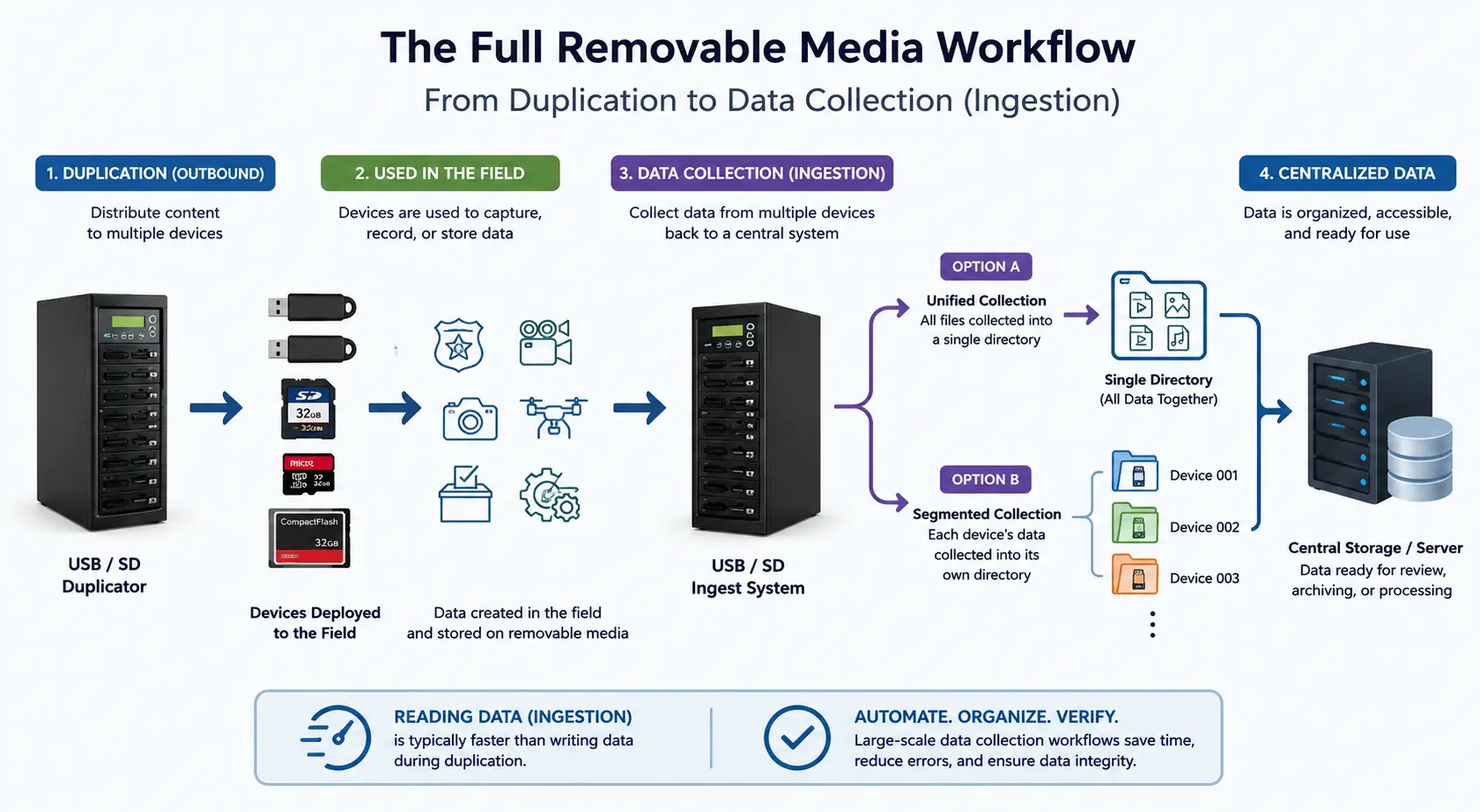
Uno de los cambios estructurales más curiosos que están ocurriendo ahora mismo en la infraestructura de IA es que algunas de las mejoras de rendimiento más importantes ya no vienen de la velocidad bruta del procesador. En cambio, vienen de una disciplina de ingeniería mucho más práctica: evitar trabajo redundante.
Aunque optimizar la ejecución redundante puede sonar como un pequeño ajuste de software, se ha convertido rápidamente en un pilar arquitectónico clave para los sistemas modernos de inferencia de IA, especialmente a medida que los modelos grandes de lenguaje (LLM) siguen creciendo en tamaño de ventana de contexto y complejidad estructural.
Aquí es donde Key-Value Caching (KV Cache) deja de ser una optimización de software de nicho y se convierte en un requisito fundamental de hardware.
A lo largo de esta serie en curso, hemos analizado cómo las cargas de trabajo modernas de IA están poniendo a prueba los límites del diseño de hardware estándar. Exploramos por qué los servidores ya no pueden depender solo de la NAND flash estándar, cómo la High Bandwidth Memory (HBM) mantiene saturadas las canalizaciones de datos y dónde la Storage Class Memory (SCM) cubre el espacio arquitectónico entre la DRAM y el almacenamiento persistente. También hemos cubierto el papel creciente de la High Bandwidth Flash, las limitaciones de la DRAM por sí sola, la realidad económica persistente de los discos duros a gran escala y la migración de toda la industria hacia el almacenamiento computacional.
KV Cache funciona como el hilo invisible que conecta todas estas capas de hardware. Porque una vez que un modelo de IA alcanza escala empresarial, el cuello de botella operativo principal ya no consiste solo en generar inteligencia, sino en recordar lo que ya fue procesado sin pagar una y otra vez el enorme costo computacional de recalcularlo.
Qué es realmente KV Cache
En esencia, KV Cache significa Key-Value Cache. Es una técnica especializada de optimización de memoria diseñada para eliminar redundancia computacional en modelos de IA basados en transformers.
Para entender su función, piensa en cómo un LLM procesa texto. Cada vez que un modelo evalúa una secuencia, traza relaciones internas complejas (pesos de atención) que determinan cómo interactúan palabras, frases y el contexto histórico del prompt. En un entorno estándar de ejecución sin estado, recalcular estas matrices matemáticas para cada palabra consecutiva saturaría tanto los núcleos de la GPU como el ancho de banda de memoria disponible del sistema.
KV Cache resuelve esto almacenando temporalmente las “Keys” y “Values” de tokens procesados previamente en memoria rápida. Al conservar intactos estos estados matemáticos, el modelo puede reutilizarlos al instante para generar el siguiente token de una secuencia, en lugar de reconstruir el historial contextual desde cero. En pocas palabras, el sistema conserva su hilo matemático de pensamiento a medida que la conversación se expande.
El cuello de botella se mueve del cálculo al control del flujo
La creciente dependencia de KV Cache deja ver una realidad más amplia: los sistemas modernos de IA ya no funcionan como calculadoras aisladas que trabajan en ráfagas intensas. Operan como flujos continuos de datos.
Cada prompt entrante, cada token generado y cada flujo de trabajo de agentes con múltiples turnos crea una dinámica continua y fluida que el hardware subyacente debe manejar en tiempo real. Aunque la cobertura tecnológica general se enfoca mucho en los teraflops brutos de una GPU, el despliegue de hardware a escala cuenta otra historia. Una vez que las cargas de inferencia se distribuyen entre millones de usuarios empresariales concurrentes, el desafío de ingeniería se aleja de los picos de cómputo y se dirige directamente a mantener un flujo de memoria estable e ininterrumpido.
En este entorno, KV Cache funciona menos como almacenamiento estático y más como un controlador de tráfico de infraestructura.
La analogía de la presa hidroeléctrica
Para visualizar esta dinámica, imagina una enorme presa hidroeléctrica que suministra energía a una red regional. El río entrante representa el flujo continuo de prompts de usuarios y tokens contextuales. La GPU actúa como el sistema pesado de turbinas, convirtiendo ese flujo de agua cinética en salida computacional utilizable.
Sin un mecanismo de caché, el sistema tendría que bombear el agua de regreso río arriba cada vez que la red solicitara un watt adicional de energía. Incluso con las turbinas más eficientes del mundo, este movimiento constante, repetitivo y de ida y vuelta introduciría una latencia operativa severa, un enorme desperdicio de energía e inestabilidad sistémica.
KV Cache reestructura este flujo de trabajo actuando como un depósito altamente controlado colocado justo detrás de las turbinas. En lugar de obligar a los datos a pasar otra vez por todo el circuito estructural, el sistema mantiene listo para usarse el contexto más crítico e inmediato.
Esta estabilidad localizada es vital porque la velocidad a la que los datos alimentan el motor de cómputo determina la eficiencia de todo el rack. Si el depósito no puede suministrar datos con suficiente rapidez, las costosas arquitecturas GPU se quedan inactivas, esperando a que los ciclos de memoria alcancen el ritmo necesario. El problema moderno de optimización es bastante claro: las plataformas de IA no solo necesitan pensar rápido; también necesitan recordar rápido.
Por qué las ventanas de contexto masivas tensionan la jerarquía de memoria
Esta presión arquitectónica se acelera de forma dramática a medida que las ventanas de contexto comerciales pasan de unos pocos miles de tokens a millones de tokens.
Mientras una breve interacción con un chatbot de atención al cliente requiere una sobrecarga mínima de memoria activa, las tareas profundas de razonamiento empresarial —como analizar repositorios legales masivos, revisar bases de código completas o ejecutar agentes autónomos— cambian las matemáticas por completo. Bajo estas condiciones, el depósito de memoria requerido se vuelve inmenso, exigiendo que el hardware conserve enormes arreglos de datos contextuales mientras mantiene respuestas por debajo del milisegundo.
Este es el punto exacto de inflexión donde los algoritmos de caché por software chocan con las restricciones físicas del hardware:
- HBM es necesaria porque el límite inmediato de la GPU exige un ancho de banda de memoria sin precedentes.
- DRAM se implementa porque las cargas de trabajo empresariales activas requieren grupos de capacidad más grandes de lo que HBM puede escalar económicamente.
- Storage Class Memory (SCM) se introduce para suavizar la brecha física de latencia entre la DRAM del sistema y las capas persistentes de flash.
- High Bandwidth Flash y los discos duros de alta capacidad administran los conjuntos de entrenamiento subyacentes de múltiples terabytes y los almacenes de datos de archivo.
Debido a que cada megabyte de datos contextuales almacenados en caché introduce un intercambio directo entre latencia localizada, costo de hardware y consumo térmico de energía, el objetivo final de la ingeniería moderna de IA está cambiando. La infraestructura de IA más eficiente de la próxima década no será necesariamente la que presuma el techo teórico de cómputo más alto; será el sistema construido para minimizar el movimiento de datos y eliminar por completo los cálculos redundantes.
Serie sobre infraestructura de memoria para IA
Este artículo es la octava entrega de nuestra serie de análisis profundo sobre cómo las cargas de trabajo empresariales de IA están remodelando las arquitecturas modernas de memoria, almacenamiento y cómputo. Lee nuestras entregas anteriores para tener más contexto de base:
- Entrega uno:
La NAND no va a desaparecer, pero los servidores de IA ahora dependen de algo más que solo flash - Entrega dos:
Qué es la High Bandwidth Memory (HBM) y por qué la IA depende de ella - Entrega tres:
Storage Class Memory explicada: la capa que falta entre DRAM y NAND - Entrega cuatro:
High Bandwidth Flash: ¿por fin la NAND puede comportarse como memoria? - Entrega cinco:
Por qué la DRAM sola ya no puede seguirle el ritmo a la IA - Entrega seis:
Por qué los discos duros siguen siendo críticos para la infraestructura de IA - Entrega siete:
Por qué la IA está moviendo el procesamiento más cerca del almacenamiento - Entrega ocho: KV Cache explicada: por qué la memoria de IA empieza a importar más que el cómputo bruto